Simply sign up and enjoy,
3-Month Free Subscription
Click Here
Home About
About
SnaPeaks
개발 배경
정보 부재로 인한 천연물 질량분석 한계 극복
MS/MS Spectral Database of Natural Products
-
기술 현황
- 천연물 데이터베이스는 이미 구축되어 현재 30만개 가량의 천연물 정보를 담고 있으나, 분자구조와 천연물에 대한 기원 정도를 포함하고 있는 수준입니다.
- 천연물 대상 MS/MS 질량분석 데이터는 거의 없습니다.
- 천연물 대상 물성 및 생리활성 데이터도 거의 없습니다.
-
문제점
- 미지의 천연 추출물을 질량분석을 통해서 성분을 분석하려 해도 MS/MS 스펙트럼 라이브러리의 부재로 성분 분석에 어려움이 많습니다.
- 유효 성분의 물질 규명 불가로 물성 및 생리활성 확인에 어려움이 많습니다.
- 결국 천연물 추출을 통한 유효성분의 제품화에도 어려움이 많습니다.
-
개발 목표
- 천연물에 대해 탄뎀질량분석(MS/MS) 데이터를 얻습니다.
- 탄뎀질량분석 스펙트럼 라이브러리를 포함한 데이터베이스와 비교하여 유효성분을 확인합니다.
제품 및 형태
제품명 :
SnaPeaks
서비스 형태
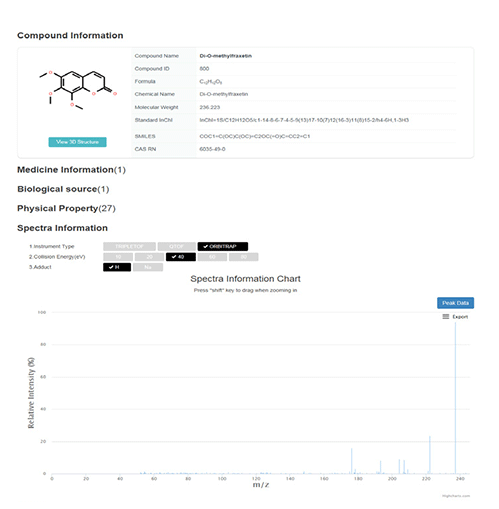
- 화합물 이름, 분자 구조식, 화합물 식별정보 검색을 통한 MS/MS 스펙트럼 확인
- 장비를 통해 나온 스펙트럼 데이터로 유효성분의 구조, 특성 정보 분석
사용자 정보
- 기기원시 데이터
- Centroid data
- 조각이온 리스트
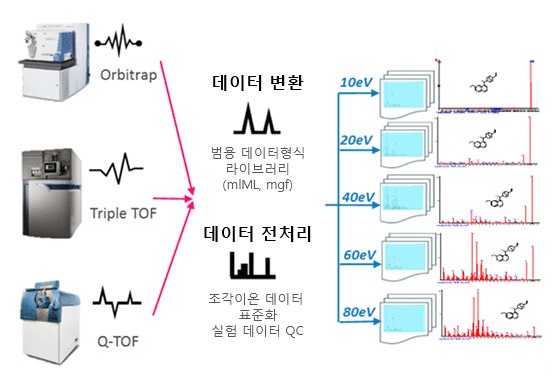
기기범용 인터페이스
- 데이터 형식 변환모듈
검색,분석 및 예측 시스템
- MS 동위원소 패턴인식
- 조각이온 패턴인식
- 통합검색 데이터베이스
- 실험에서 얻어진 조각이온 데이터베이스
- 색인기
정보 생성
- 특정 화합물 존재 여부
- 물리화학적 성질
- 알려진 생리활성
제품 용도
천연물 유효성분의 확인
- 천연물 이차대사체 성분 분석 적용분야
- 각 산업분야에서 천연물의 유효 성분을 바로 분석해서 물성 정보를 확인 할 수 있습니다.
-
유효 성분이 포함된 약재 정보를 제공하여 추출할 천연물 대상을 넓힐 수 있습니다.
제품 장점
하이엔드 질량분석기에 기반한 MS/MS 라이브러리와 천연물 정보 검색 시스템을 경험하세요.
-
이차대사체 조각이온화 데이터베이스
-
MS/MS 검색 알고리즘 개발 및 상용서비스 구축n
천연 추출물의 성분을 분석하는 기술
- 표준시료를 고분해능 질량분석기를 사용하여 분석하였습니다.
- 다양한 에너지 준위에서 얻어진 MS/MS 스펙트럼이 라이브러리에 포함되어 있습니다.
- MS/MS 스펙트럼 데이터베이스는 물질의 화학적 구조와 인공지능 기반의 알고리즘을 통해 검증되었습니다.
성분 분석을 위한 라이브러리 및 데이터베이스
- 천연물에 대한 전기분무이온화(ESI) 기반의 MS/MS 스펙트럼 라이브러리를 구축하고 확장합니다.
- 3종의 장비를 통해 얻어진 방대한 MS/MS 스펙트럼을 탐색합니다.
- 사용자 측정 데이터 형식 지원하여 편의성을 제공 합니다.
개선된 UI & UX
- 화합물 이름, 분자 구조식, 화합물 식별정보, 스펙트럼을 통한 검색이 가능합니다.
- 화합물 기본정보, 물성정보, 약재 정보를 제공합니다.
제품 스펙
데이터는 더 방대해지고 검색 성능은 더 향상되었습니다.
| 천연화합물 수 | 2,600+ 점 |
|---|---|
| 조각 이온화 수 | 70,000+ 점 |
| 적용가능 MS 장비 | 6종 이상 |
| 패턴 인식화 참조 에너지 수 | 3 점 |
| 검색엔진 속도 | 17,000 spectra/sec |
| 검색엔진 성능* | 97% |
|---|---|
| Instrument Type | TripleTOF / Q-TOF / Orbitrap |
| 이온화 방법 | 전기분무이온화 |
| Fragmentation Method |
Collision Induced Dissociation (CID) Higher Energy Collisional Dissociation (HCD) |
| Adduct Ion | [M+H]+ / [M+Na]+ |
* 검색엔진 성능 평가는 MassBank 성능 평가 방식에 준함.
정확도 = (True positive + True negative) / (True positive + True negative + False positive + False negative)
유사도 랭크 10위 이내는 positive로 간주